Organisations across industries are adopting ISO/IEC 42001:2023 for responsible development, deployment, and management of Artificial Intelligence Management Systems (AIMS). Experimental pilots have moved into production at an unprecedented speed. Core workflows are now driven by machine-learning models operating across interconnected software ecosystems, often outpacing governance maturity.
Before AI governance can be effective, more fundamental questions need to be addressed: What is an AI system? How do AI systems fail? Why do those failures occur?
An AI system is an engineered, machine-based system designed to generate outputs in pursuit of human-defined objectives. Unlike deterministic software, AI systems operate probabilistically, inferring patterns from data rather than executing explicit logic.
As a result, AI systems fail in ways that are often non-deterministic and difficult to trace, arising from underlying weaknesses rather than isolated errors. These failures and the reasons behind them can be systematically understood across four core risk pillars.
This blog looks at those four structural pillars of AI risk and the control architecture needed to govern them under ISO/IEC 42001:2023 Annex A. Each pillar is addressed through two complementary layers:
I. Technical controls: Safeguards embedded within the data pipelines, model design, validation processes, and runtime environments.
II. Operational controls: Governance, accountability, lifecycle management, and documented oversight aligned with Annex A control objectives.
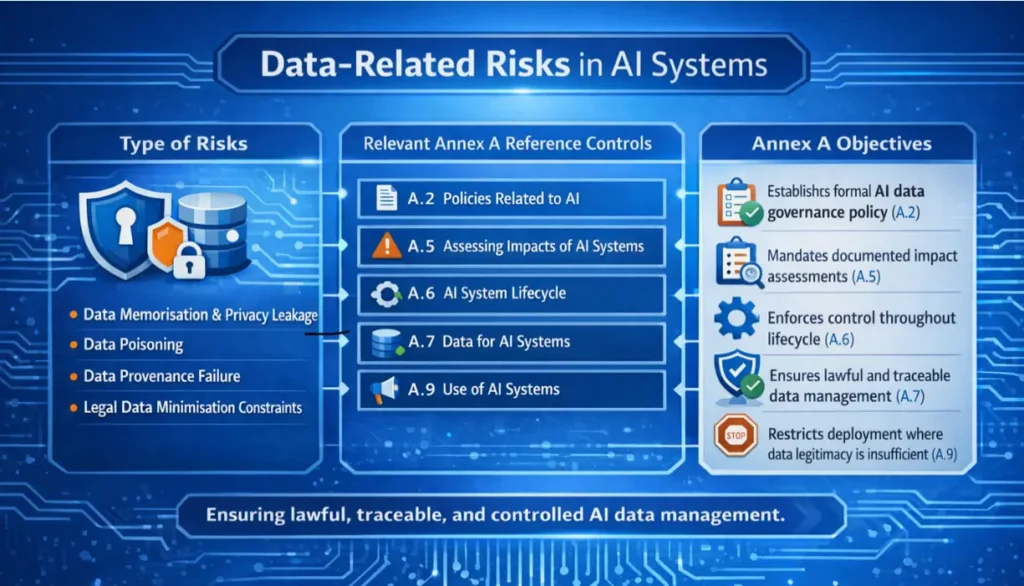
1. Data-related Risks:
The Structural Bedrock Data forms the structural foundation of every AI system. If that foundation is weak, downstream controls may limit the damage, but they cannot undo the structural risk embedded during training.
- Data Memorisation and Privacy Leakage: Machine learning models can internalise patterns from training data in ways not directly observable. Under specific query conditions, this can lead to the unintentional disclosure of sensitive information such as personal data, health records, proprietary code, or financial information.
This creates direct exposure under data protection and sector-specific regulations (e.g., GDPR, HIPAA, and DPDPA).
Scenario: In 2023, OpenAI’s ChatGPT exposed user conversation data and limited payment information due to a caching bug, allowing some users to view data belonging to others. This incident illustrates how AI systems can unintentionally leak sensitive information when data handling mechanisms fail under specific conditions.
- Data Poisoning: This occurs when manipulated data is introduced into a training dataset, causing the model to learn incorrect or “adversary-aligned” behaviour while still appearing statistically valid during testing. These attacks are often missed by perimeter-based controls and standard validation pipelines.
Scenario: An attacker subtly alters training data so that an anti-money-laundering model stops flagging a specific category of illegal transfer. Reports continue to show normal performance while regulatory exposure quietly increases.
- Data Provenance Failure: Data provenance refers to the ability to trace where data originates from and how it was collected, consented, processed, transformed, and used over time. Within AI governance frameworks, the inability to establish data provenance is a compliance failure regardless of model accuracy.
Scenario: Clearview AI built a facial recognition system using billions of images scraped from the internet without user consent. Regulators across multiple jurisdictions took enforcement action, not because of model inaccuracy, but because the organisation could not demonstrate lawful data collection, consent, or provenance.
- Legal Data Minimisation Constraints: Large datasets are not always usable datasets. Legal requirements around consent, purpose limitation, and retention restrict what data can be retained and reused. These constraints often remove rare or edge-case records, weakening model generalisation and increasing error rates.
Scenario: A bank restricts training data to customers with active consent and recent records to meet retention obligations. Rare fraud cases fall outside this window, leaving the model under-trained on edge conditions and more likely to miss them in production.
Controls
A. Technical Controls
- Implement differential privacy mechanisms including DP-SGD with gradient clipping and calibrated noise injection to reduce data memorisation. Apply pre-ingestion automated PII detection and redaction pipelines.
- Apply integrity verification and statistical anomaly detection on training datasets to identify manipulated or adversary aligned inputs. Apply segmented training workflows to isolated higher-risk data sources.
- Establish end-to-end data lineage tracking across the AI data lifecycle with fixed audit trails and metadata versioning, including consent status and lawful basis tagging. Implement dataset lineage mapping. Integrate formal dataset documentation into MLOps workflows to ensure traceability across transformation stages.
- Introduce synthetic data generation pipelines, with validated distributional fidelity, to supplement rare or edge-case conditions.
B. Operational Controls
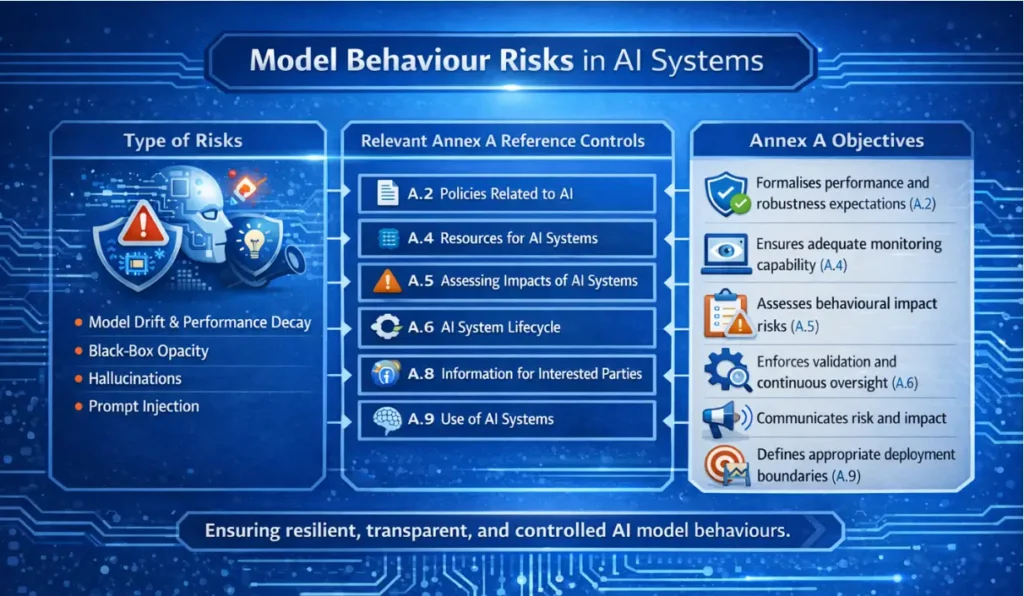
2. Model Behaviour Risks: Behavioural Drift and Instability
AI models do not reason the way humans do; they infer statistical patterns from data. The gap between what the organisation intends and what the model infers is the source of most behavioural risk.
- Model Drift and Performance Decay: Models are trained on historical data distributions, while production environments evolve. When conditions change, input distributions shift, and performance degrades gradually.
Scenario: A manufacturing plant upgrades its sensor hardware. A predictive maintenance model trained on legacy data begins misclassifying early failure indicators, resulting in unplanned downtime.
- Black-Box Behaviour and Opacity: High-capacity models, particularly deep neural networks, often lack interpretability. Outputs can be observed, but internal decision pathways cannot be meaningfully inspected or traced to specific features. This lack of traceability presents a material governance risk.
Scenario: During autonomous air combat testing conducted by the U.S. Air Force under the DARPA Air Combat Evolution (ACE) program at Edwards Air Force Base, AI systems operated in highly complex environments where decision-making processes were not fully transparent. While outputs could be observed and evaluated, the underlying reasoning remained opaque, making difficult for operators to validate behaviour or diagnose unexpected actions.
- Hallucinations and Fabricated Outputs: Generative AI systems can produce syntactically coherent and contextually plausible outputs that are factually incorrect. There is no inherent signal indicating uncertainty or fabrication of output. These failures are therefore difficult to detect through conventional testing.
Scenario: AI chatbots have generated fabricated news articles, including false allegations against individuals. In separate cases, systems have misclassified local services or businesses, presenting them inaccurately in user-facing responses.
- Prompt Injection and Behaviour Manipulation: User-facing AI systems can be manipulated through crafted inputs that alter behaviour or override constraints. These attacks exploit how models interpret instructions.
Scenario: A user frames a conversation with a retail chatbot as an internal testing exercise. The system interprets the instruction as authoritative and discloses restricted internal policy information it was not intended to reveal.
Controls
A. Technical Controls
- Implement continuous monitoring using statistical drift detection methods such as Population Stability Index (PSI) and Kullback–Leibler (KL) divergence to detect input distribution shifts.
- Apply explainability tooling including SHAP, LIME and counterfactual analysis to attribute outputs to specific input features. Maintain automated decision trace logging at inference time.
- Use retrieval-augmented generation (RAG) in generative systems where factual grounding is required. Implement confidence scoring on model outputs.
- Enforce strict input validation. Isolate system-level instructions from user-provided inputs at the architectural level. Apply policy-constrained decoding to limit output manipulation.
B. Operational Controls
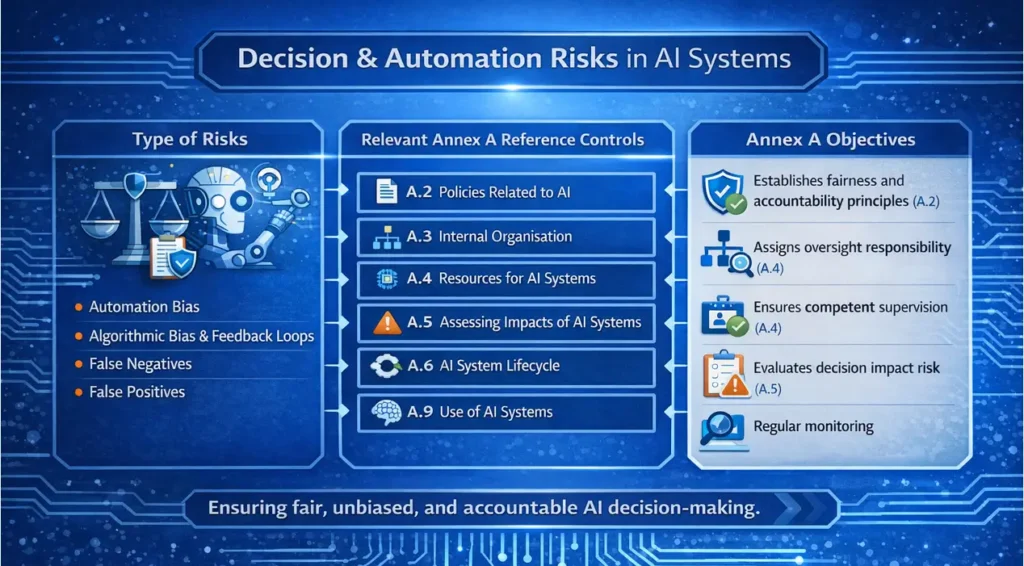
3. Decision and Automation Risks: When AI Leads
When organisations allow AI to influence or make decisions, the risk emerges not from artificial intelligence, but from inadequate oversight frameworks governing it.
- Automation Bias: Operators tend to accept AI recommendations without sufficient scrutiny, particularly when the system appears reliable or fast. Errors occur when outputs are not independently evaluated.
Scenario: A physician relies on a positive safety indication from a diagnostic AI system and skips a detailed review, missing an early-stage malignancy.
- Algorithmic Bias and Feedback Loops: Models trained on historical data often inherit embedded biases. If left unaddressed, deployment can reinforce those patterns through feedback loops. Correcting bias after deployment is significantly more complex than addressing it during system design.
Scenario: A hiring algorithm trained on historical recruitment data favours male candidates for technical roles. The company hires more men based on the AI system’s recommendations, skewing the next training dataset further and reinforcing the bias.
- False Negatives and Missed Signals: A false negative occurs when a system fails to detect a genuine issue. In security contexts, threats may go unnoticed. In compliance, violations may remain undetected. Reducing false positives can increase false negatives, so this trade-off must be carefully managed.
Scenario: An AI-based intrusion detection system fails to flag a slow-and-low data exfiltration attack. The traffic mimics legitimate administrative updates. By the time the breach is discovered, sensitive data has already been compromised.
- False Positives and Type I Errors: AI systems may incorrectly classify legitimate activity as harmful or anomalous. Although less visible than missed detections, these errors can still cause financial loss, service disruption, and customer dissatisfaction.
Scenario: In retail banking, a fraud detection model repeatedly flags legitimate transactions during a seasonal sales spike. The result is payment failures abandoned purchases and customer complaints.
Controls
A. Technical Controls
- Implement calibrated confidence scoring to quantify output uncertainty an surface it clearly within decision interfaces. Use representative and stratified datasets during training to reduce structural bias at the point of model formation.
- Apply fairness-aware learning objectives where discrimination risk is material, to embed equity constraints into the training process.
- Embed continuous automated fairness monitoring to detect drift-driven bias amplification in production.
- Apply risk-weighted threshold tuning to manage the balance between false negatives and false positives in line with defined risk tolerance.
- Deploy ensemble detection models to reduce single-model dependency in high-stakes detection tasks.
- Implement precision-recall optimisation aligned to defined business risk tolerance and validated through structured performance benchmarking.
B. Operational Controls
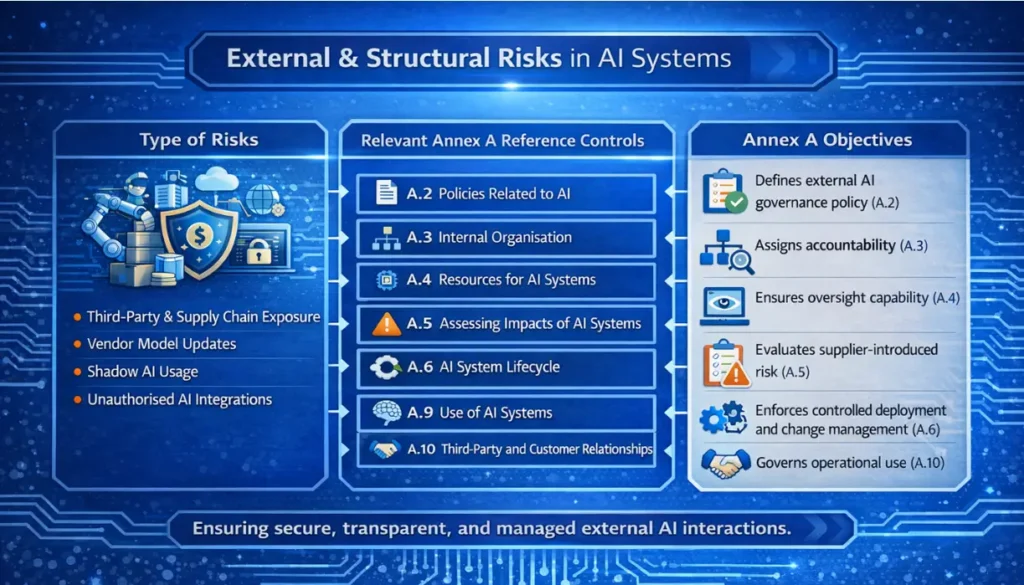
4. External and Structural Risks
Not all AI risk originates from within. Some of the most significant threats come from the supply chain, third-party vendors, and unmanaged internal usage.
- Third-Party and Supply Chain Risk: Organisations frequently rely on external API services without visibility into training data, update cycles, or model changes. A vendor update can alter system behaviour without notice, invalidating internal testing and risk assessments.
Scenario: A retail chain uses a third-party sentiment analysis API. The vendor updates the model, causing neutral customer reviews to be classified as hostile. Automated public responses are triggered unnecessarily, creating confusion and reputational risk.
- Shadow AI: Employees may use unauthorized AI tools to accelerate work. This bypasses data classification controls, security review processes, and contractual safeguards. Sensitive information may be transmitted to external providers without formal approval or oversight.
Scenario: Developers use an unapproved coding assistant that sends proprietary source code to a public cloud for processing, exposing trade secrets before the company becomes aware of it.
Controls
A. Technical Controls
- Deploy API gateways to mediate all third-party AI service access, applying automated input and output validation on all traffic.
- Enforce version pinning on external model dependencies to prevent silent behavioural changes from unsanctioned vendor updates.
- Deploy sandboxed staging environments to test third-party model updates in isolation before production release.
- Implement automated runtime output monitoring to detect behavioural drift following vendor changes.
- Deploy endpoint-level data loss prevention controls and automated outbound traffic inspection to detect and block unauthorised transmission of sensitive data.
- Implement browser isolation to restrict corporate device access to unapproved external AI services.
- Enforce role-based access control and segregated development environments to prevent proprietary data from reaching unauthorised tools or personnel.
B. Operational Controls
Technical controls strengthen the AI system itself. Operational controls govern accountability, lifecycle management and executive supervision. ISO/IEC 42001 requires traceability between identified AI risks and implemented controls. Risk identification alone is not enough. Effective AI risk management requires structured control architecture, engineered safeguards, measurable controls, and disciplined oversight.
Anzen’s AI Risk Methodology
For many organisations, AI governance remains disconnected from technical implementation. Risk registers are documented, policies are written, and controls are defined on paper. Yet, the underlying AI systems are rarely tested adversarially to verify whether they behave as governed. The result is a compliance posture that appears robust in documentation but fragile during system operation.
Anzen addresses this gap by operating across both governance and technical security domains. We specialise in AI red teaming and adversarial security testing such as LLM penetration testing, model extraction analysis, prompt injection assessment, RAG pipeline vulnerability testing, and evaluation of agentic AI risks aligned with the OWASP Top 10 for LLMs.
This hands-on exposure gives us direct insight into how AI systems fail in practice. When we design AIMS controls, they are informed by observed attack vectors and real operational failure modes rather than theoretical risk categories.
For organisations pursuing ISO/IEC 42001 certification or deploying AI systems at scale, Anzen brings structured AIMS implementation that translates AI risk into proper governance and compliance outcomes.
Use Case: Securing Customer-Facing GenAI Applications
Organisations deploying customer-facing generative AI systems often recognise prompt injection as a potential risk but rarely test it beyond documentation.
In one BFSI client deployment, a GenAI assistant integrated with internal knowledge sources through a RAG pipeline was exposed to prompt manipulation attempts designed to override system instructions and retrieve restricted information.
Rather than treating prompt injection as a theoretical risk category, we conducted adversarial testing to simulate manipulation attempts against the application.The testing identified specific pathways through which user prompts could influence system instructions and access unintended data sources.
Based on these findings, lifecycle controls were introduced across the system architecture, including development guardrails, prompt isolation mechanisms, and runtime monitoring for anomalous prompt patterns. By linking the identified vulnerability to specific technical and operational controls, governance moved beyond documentation and into enforceable system safeguards.
The transition from risk to resilience is not automatic; it requires disciplined integration of system design, monitoring architecture, governance structures, and executive accountability. To start building resilient AI governance, reach out to Anzen Technologies Pvt Ltd.